What Are Tokens in AI? How LLMs Process and Price Your Text
Tokens are the hidden currency of AI. Every prompt you send and every response you receive is measured in them — and understanding how they work can save you real money.
If you have ever used the OpenAI API, Claude, or Gemini, you have seen "tokens" on your billing page. But what are tokens in AI, exactly? They are not words. They are not characters. They are something in between — and the way AI models split your text into tokens directly determines how much you pay for every single API call.
I spent an embarrassing amount of money on API calls before I actually understood tokenization. A prompt I assumed was "about 100 words" turned out to be over 180 tokens. A JSON payload I sent to GPT-4o every 30 seconds racked up $47 in a single afternoon because I never checked the token count. Once I started paying attention to how tokenizers actually work, my monthly API bill dropped by about 40%.
This guide covers everything you need to know: what tokens are, how the tokenization algorithm works, why different models count tokens differently, and practical ways to reduce token usage without sacrificing quality. Whether you are building an AI product, experimenting with APIs, or just curious about how ChatGPT processes your messages, you will walk away understanding the atomic unit that powers every large language model on earth.
What Is a Token, Exactly?
A token is the smallest unit of text that an AI model reads. When you type "I love programming" into ChatGPT, the model does not see three words. It sees a sequence of tokens — subword chunks that the model's tokenizer has learned to recognize during training.
Here is a concrete example. The sentence "Tokenization is fascinating" gets split like this by GPT-4o's tokenizer:
That is four tokens. Notice that "Tokenization" was split into "Token" and "ization" — two subword pieces — while "is" and "fascinating" each stayed as a single token. Spaces are typically attached to the beginning of the following token, not treated as separate tokens.
Why not just use whole words? Because a word-level system would need a vocabulary entry for every word in every language — millions of entries, including "unhappiness," "unhappily," "unhappy," and every other variation. Subword tokenization solves this elegantly. The tokenizer learns common fragments like "un," "happy," "ness," and "ly," then assembles them as needed. A vocabulary of 100,000 tokens can represent virtually any word in any language, including words the model has never seen before.
Some quick rules of thumb for English text, based on OpenAI's documentation:
- 1 token ≈ 4 characters of English text
- 1 token ≈ ¾ of a word
- 100 tokens ≈ 75 words
- A short paragraph (50 words) is about 65–70 tokens
- A full page of text (~500 words) is roughly 650–700 tokens
But these are averages for English. As we will see later, other languages — especially Chinese, Japanese, and Korean — produce very different ratios.
How Tokenization Works: BPE Explained Simply
The algorithm behind most modern tokenizers is called Byte Pair Encoding, or BPE. It was originally a data compression technique from 1994, adapted for natural language processing by researchers at the University of Edinburgh in 2015. Today, GPT-4o, Claude, and most large language models use some variant of BPE.
Here is how BPE builds its vocabulary, step by step:
Step 1: Start with individual characters. The algorithm begins with the smallest possible units — individual bytes or characters. So "tokenizer" starts as: t o k e n i z e r.
Step 2: Count every pair of adjacent characters across the entire training corpus. If the pair "e" + "r" appears most frequently, it gets merged into a new token: "er".
Step 3: Repeat. Now count pairs again with the merged tokens. Maybe "iz" + "er" appears often, so it becomes "izer". Then "token" + "izer" merges into "tokenizer" if it appears enough times. This process repeats thousands of times until the vocabulary reaches its target size.
The result is a vocabulary that looks something like this:
unbelievably → 3 tokens
Hello, world! → 4 tokens
The quick brown fox → 4 tokens
Common English words like "the," "and," "is" almost always become single tokens. Uncommon or technical words get split into subword pieces. A word the tokenizer has never seen — say, a made-up product name like "Zyphlonix" — will get broken into several small fragments: perhaps "Z" + "yph" + "lon" + "ix."
This is why proper nouns and technical jargon tend to consume more tokens per word than everyday language. Your code variable named getUserAuthenticationStatus is going to cost more tokens than "get the login status" — even though they mean roughly the same thing.
A Note on Vocabulary Size
GPT-4o uses a vocabulary of roughly 200,000 tokens — double the ~100,000 of GPT-3.5's tokenizer (cl100k_base). A larger vocabulary means more words can be represented as single tokens, which generally means fewer tokens per message. This is one reason GPT-4o is more token-efficient than its predecessor, especially for non-English languages and code.
Why Token Count Matters for AI Costs
Every major AI provider charges by the token. Not by the word, not by the message, not by the minute — by the token. And there is a critical distinction most beginners miss: input tokens and output tokens are priced differently.
When you send a prompt to an API, you pay for the input tokens (your prompt) and the output tokens (the model's response). Output tokens are almost always more expensive — typically 2–5 times the input price — because generating text requires more computation than reading it.
Here is what the major models cost as of March 2026:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 128K tokens |
| GPT-4o mini | $0.15 | $0.60 | 128K tokens |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens |
Let me make these numbers concrete. Say you are building a customer support chatbot that processes 10,000 conversations per day. Each conversation averages 800 input tokens and 400 output tokens. Here is your daily cost across models:
| Model | Daily Input Cost | Daily Output Cost | Daily Total | Monthly Total |
|---|---|---|---|---|
| GPT-4o | $20.00 | $40.00 | $60.00 | $1,800 |
| GPT-4o mini | $1.20 | $2.40 | $3.60 | $108 |
| Claude Sonnet 4.6 | $24.00 | $60.00 | $84.00 | $2,520 |
| Gemini 2.5 Flash | $2.40 | $10.00 | $12.40 | $372 |
The difference between Claude Sonnet and Gemini Flash for the same workload is $2,148 per month. That is not a rounding error. That is the difference between a viable product and a money pit. Understanding token pricing is not academic — it is the single most important cost lever for any AI application.
The Context Window Tax
There is another cost dimension most people overlook: the context window. Every token in your conversation history — your system prompt, previous messages, function definitions, few-shot examples — gets re-sent with every API call. A system prompt alone can be 500–2,000 tokens. If your chatbot has a 10-message history, you are potentially sending thousands of tokens of context before the user's actual question even gets counted.
This is why long-running conversations get expensive fast. By message 20, you might be sending 8,000 tokens of history just to ask "What time does the store close?" Trimming context aggressively — summarizing old messages, dropping irrelevant turns, capping history length — is one of the highest-impact optimizations you can make.
How Different AI Models Count Tokens (OpenAI, Claude, Gemini)
Here is a fact that surprises most people: the same text produces different token counts in different models. Each provider trains its own tokenizer with its own vocabulary, so the token boundaries fall in different places.
Take the sentence "The quick brown fox jumps over the lazy dog." Here is how different tokenizers handle it:
| Tokenizer | Token Count | Used By |
|---|---|---|
| o200k_base | 9 tokens | GPT-4o, GPT-4o mini |
| cl100k_base | 9 tokens | GPT-3.5, GPT-4 |
| Claude tokenizer | 10 tokens | Claude Sonnet 4.6, Haiku |
| Gemini tokenizer | 10 tokens | Gemini 2.5 Pro, Flash |
For simple English sentences the differences are small. But they compound. A 10,000-word document might be 13,200 tokens on GPT-4o and 14,800 on Claude — a 12% difference that directly affects your costs.
The CJK Problem: Languages That Cost More
The most dramatic tokenization differences appear across languages. English text is heavily represented in training data, so English words tend to get efficient, compact token representations. But languages that use non-Latin scripts — especially Chinese, Japanese, and Korean (CJK) — often require 2–3 times more tokens to express the same meaning.
Consider this example:
| Text | Language | Characters | GPT-4o Tokens |
|---|---|---|---|
| "Hello, how are you?" | English | 20 | 6 |
| "Hola, ¿cómo estás?" | Spanish | 19 | 7 |
| "Bonjour, comment allez-vous ?" | French | 30 | 8 |
| "안녕하세요, 어떻게 지내세요?" | Korean | 14 | 8 |
| "你好,你怎么样?" | Chinese | 8 | 4 |
Korean uses fewer characters but produces more tokens than the English equivalent. This means that Korean or Chinese users of AI APIs are effectively paying a language tax — the same conversation costs significantly more simply because of the language it is conducted in.
GPT-4o's larger vocabulary (200K vs 100K) has improved this disparity compared to older models. OpenAI reported that GPT-4o uses roughly 30–50% fewer tokens for non-English languages compared to GPT-4, thanks to its expanded tokenizer. But the gap has not disappeared entirely.
Tokens in Code
Code is another area where tokenization gets expensive. Programming languages use lots of special characters, indentation, and long variable names — all of which consume tokens. A line of Python like def calculate_monthly_payment(principal, rate, years): uses about 12 tokens. The equivalent natural language description "define a function to calculate monthly payment given principal, rate, and years" uses about 14 tokens — surprisingly close. But JSON payloads with deeply nested keys, repeated field names, and verbose formatting can be extremely token-heavy.
Tips to Reduce Token Usage and Save Money
Now for the part you are actually here for. I have spent months optimizing token usage for production AI applications, and these are the techniques that made the biggest difference.
1. Trim your system prompt ruthlessly
Your system prompt gets sent with every single API call. If it is 1,500 tokens, a chatbot with 100 daily users making 20 requests each will burn 3 million system-prompt tokens per day — just on the instructions. Write your system prompt like a telegram: every word must earn its place. Cut examples that do not change behavior. Remove redundant instructions. I have seen system prompts shrink from 2,000 tokens to 400 with zero change in output quality.
2. Manage conversation history aggressively
Do not blindly send the entire conversation history with every request. Strategies that work:
- Sliding window: Keep only the last N messages (e.g., last 10 turns)
- Summarization: Periodically summarize older messages into a compact paragraph
- Relevance filtering: Drop messages that are not relevant to the current question
A rolling summary of older context plus the last 5–8 messages is usually enough to maintain coherent conversation without sending thousands of history tokens.
3. Use shorter output instructions
Remember, output tokens cost 2–5 times more than input tokens. If you only need a yes/no answer, tell the model: "Respond with only YES or NO." If you need structured data, ask for JSON with minimal keys. Do not let the model write three paragraphs when three words would suffice. The instruction "Be concise. Maximum 2 sentences." in your system prompt can cut output token usage by 50% or more.
4. Choose the right model for the task
Not every request needs the most powerful (and most expensive) model. A common pattern is to route simple queries to cheaper models and reserve expensive models for complex reasoning. GPT-4o mini costs just $0.15 per million input tokens and Gemini 2.5 Flash costs $0.30 — that is 10–20 times cheaper than Claude Sonnet for input. For tasks like classification, extraction, and simple Q&A, the cheaper models perform nearly as well.
5. Cache and deduplicate
If multiple users ask similar questions, cache the responses. If your application sends the same few-shot examples or function schemas with every call, consider whether they truly need to be included every time. Anthropic's prompt caching lets you cache the static prefix of your prompts, reducing costs by up to 90% on cached tokens.
6. Prefer JSON over verbose text
When sending structured data to the model, use compact JSON with short keys. Instead of "customer_full_name", use "name". Instead of "order_total_amount_usd", use "total". These small savings add up fast when you are processing thousands of records.
7. Count tokens before sending
The simplest optimization is also the most overlooked: actually count your tokens before making the API call. Most developers guess, and most guesses are low. Use SudoTool's AI Token Counter to paste your prompt and see the exact token count across GPT-4o, Claude, and Gemini, along with the estimated cost. Knowing the number changes behavior — once you see that your prompt is 3,200 tokens instead of the 800 you assumed, you will find ways to trim it.
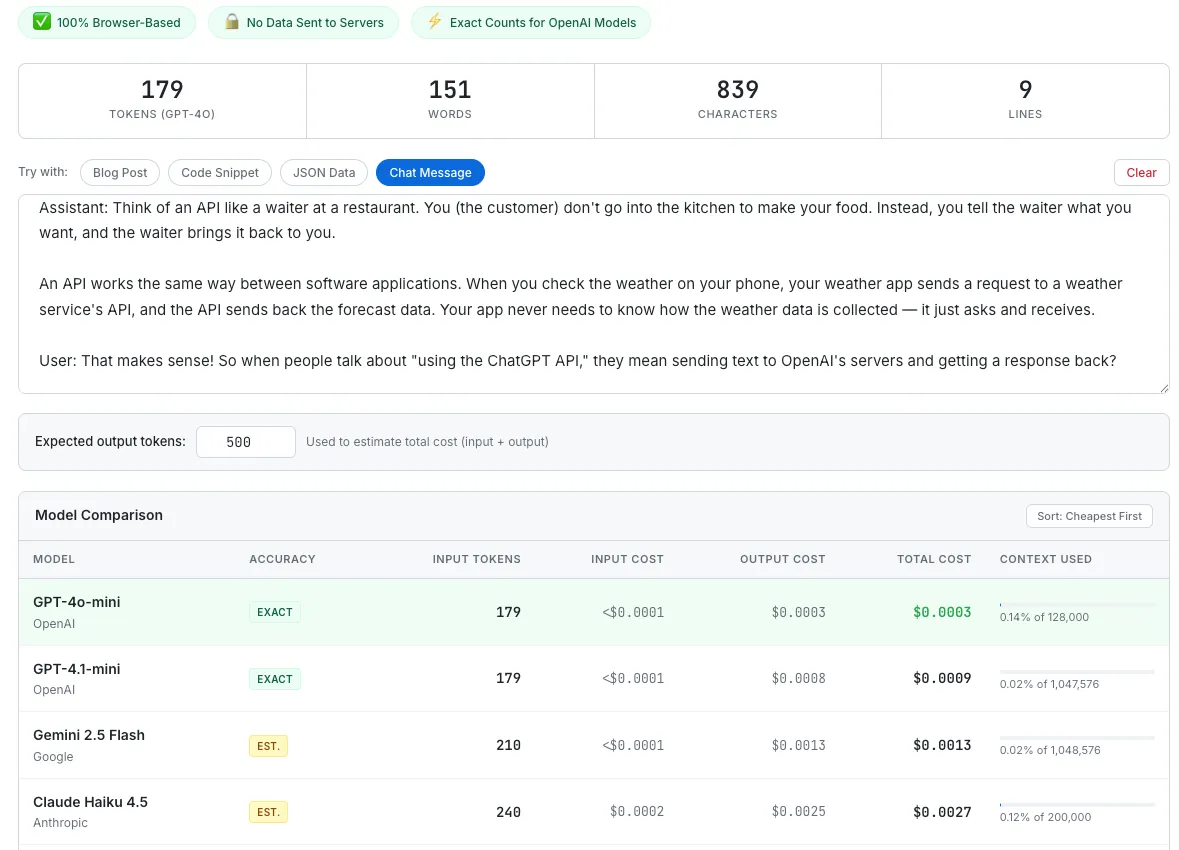
SudoTool's AI Token Counter lets you paste text and instantly see token counts and cost estimates across multiple models.
Frequently Asked Questions About AI Tokens
What is a token in AI?
A token is the smallest unit of text that a large language model processes. Tokens are subword fragments — common words like "the" or "and" are single tokens, while uncommon words get split into smaller pieces. In English, one token is roughly 4 characters or three-quarters of a word.
How many tokens are in a word?
On average, one English word equals about 1.3 tokens. Common words like "I," "the," and "is" are single tokens. Longer or less common words get split into multiple tokens. For example, "unbelievably" might be 3 tokens: "un" + "believ" + "ably." As a rough estimate, 750 words is approximately 1,000 tokens.
Why do different models produce different token counts?
Each AI provider trains its own tokenizer with a different vocabulary. GPT-4o uses a ~200,000-token vocabulary (o200k_base), while GPT-3.5 used ~100,000 (cl100k_base). Claude and Gemini have their own tokenizers as well. Because the vocabularies differ, the same text gets split at different boundaries, producing different counts.
Do spaces count as tokens?
Spaces are typically not separate tokens. Instead, they get attached to the beginning of the following word. So " world" (with a leading space) is a single token. This is a detail of how BPE tokenizers encode whitespace — it means spaces generally do not add extra tokens to your count.
Why does Chinese or Korean text use more tokens?
BPE tokenizers build vocabularies primarily from training data, which is overwhelmingly English. English words get efficient, compact representations. CJK characters appear less frequently in training data, so each character often maps to one or more tokens. A Korean sentence can use 2–3 times more tokens than an English sentence with the same meaning. GPT-4o's larger vocabulary has reduced this gap compared to older models, but it still exists.
What is the difference between input and output tokens?
Input tokens are the tokens in your prompt — everything you send to the model. Output tokens are the tokens the model generates in its response. Output tokens are more expensive (typically 2–5 times the input price) because generating text requires more computation than processing it. Both input and output tokens count toward the model's context window limit.
What is a context window?
The context window is the maximum number of tokens a model can process in a single request, including both input and output. GPT-4o supports 128K tokens, Claude Sonnet 4.6 supports 1M tokens, and Gemini 2.5 Pro supports up to 1 million tokens. When you exceed the context window, the API will return an error — you cannot simply send unlimited text.
How can I count tokens before making an API call?
For OpenAI models, you can use the tiktoken library in Python. For Anthropic models, see the Anthropic token counting docs. Or you can use SudoTool's AI Token Counter to paste text and get instant counts across GPT-4o, Claude, and Gemini — entirely in your browser.
Start Counting Your Tokens
Tokens are the fundamental unit of AI — every prompt, every response, every dollar on your API bill traces back to them. The good news is that once you understand how tokenization works, optimizing becomes straightforward. Trim your system prompts, manage conversation history, route to cheaper models when you can, and — most importantly — actually measure your token usage before guessing.
If you are building anything with AI APIs, I genuinely recommend spending 10 minutes pasting your actual prompts into a token counter. The gap between what you think your prompts cost and what they actually cost is almost always larger than you expect. That gap is where the savings live.
For more on how costs add up in everyday work, check out our guide to the true cost of meetings — a different kind of per-unit pricing, but the same lesson about making invisible costs visible.