What Is Fake Data and Why Developers Need It for Testing
71% of companies use real production data in their test environments — and it's costing them millions in breaches, fines, and compliance failures. Here's why fake data isn't just convenient, it's essential.
Every team that builds software needs to test it — and testing requires data. Whether a signup form validates correctly, whether a payment system can handle thousands of orders, whether a table breaks when it encounters a null value — you need realistic data to answer these questions. Increasingly, teams are turning to fake data for testing instead of copying production databases. The question is why that matters, and what happens when you get it wrong.
According to Redgate's State of the Database Landscape survey, 71% of enterprises use a full-size production backup or a subset of production data in their development and testing environments. Real customer names, email addresses, credit card numbers, and medical records are being copied into development servers with far weaker security than production. The IBM Cost of a Data Breach Report 2024 puts the global average cost of a single data breach at $4.88 million — a 10% increase year over year and the largest spike since the pandemic.
The fix is straightforward — use fake data instead of real data. Fake data (also called synthetic data, mock data, or test data) mimics the format and patterns of real data without containing a single piece of information tied to an actual person. This guide covers what fake data is, why using production data in testing is dangerous, which regulations you may already be violating, and how to generate effective fake data for your workflows.
What Is Fake Data? Understanding Test Data Types
"Fake data" is a broad term for any data that is artificially generated for use in software development and testing instead of real data. But under that umbrella, several distinct types exist — each with different generation methods, fidelity levels, and trade-offs. Understanding these differences matters if you want to choose the right approach for your project.
Mock data and stubs. The simplest form. In unit testing, mocks and stubs replace external dependencies with predetermined responses. Instead of calling a live payment gateway, your test uses an object that returns { status: "success", transactionId: "mock-123" }. As Martin Fowler explains in his well-known article Mocks Aren't Stubs, mocks verify that expected calls were made, while stubs simply return canned responses.
Synthetic data. Generated by algorithms or machine learning models (such as GANs and VAEs) to statistically replicate the distributions and patterns of real-world data — without representing any real individual. According to the Perforce 2025 State of Synthetic Data Report, 62–74% of global enterprises now use synthetic data for software testing. Gartner predicted in 2021 that 60% of data used for AI development would be synthetically generated by 2024 — a forecast that signaled the scale of the shift toward artificial data.
Anonymized and masked data. Starts from real production data, but replaces personally identifiable information (PII) through substitution, scrambling, or tokenization. "John Smith" becomes "Alex Brown"; a real email becomes a randomized string. This approach preserves the relationships and distributions of the original data — an advantage for realistic testing — but carries a residual risk of re-identification that pure synthetic data avoids.
Fixtures. Predefined, static datasets stored as JSON files or SQL scripts and loaded before each test run. They ensure identical starting conditions for repeatable tests. Fixtures are predictable and reliable, but they become difficult to maintain as schema complexity grows.
Rule-based generated data. Produced by libraries like Faker.js or online generators using deterministic rules — random first names from a dictionary, emails composed from name parts and common domains, phone numbers following locale-specific formats. This data looks realistic but is entirely fictional. It can be generated in bulk, making it ideal for load testing, database seeding, and UI prototyping.
The essential distinction is this: production data is real information about real people. Fake data looks real but belongs to no one. That difference has profound implications for security, compliance, and development velocity.
The Hidden Danger of Using Real Data in Testing
"It's just the test environment — it's fine." That assumption has led to some of the most costly data breaches in recent history. Attackers know that test and staging environments often have weaker security than production, and they deliberately target them.
Kiddicare — 794,000 customers exposed via a test website. In 2016, the UK baby products retailer Kiddicare suffered a data breach that exposed the names, delivery addresses, email addresses, and phone numbers of up to 794,000 customers. The data was stolen not from the live production site, but from a test version of the website that had been loaded with a real customer dataset from November 2015. Customers began receiving phishing text messages — the first sign that something was wrong.
Microsoft — a legacy test account opened the door to executive emails. In late 2023, the Russian state-sponsored group Midnight Blizzard (also known as Nobelium) compromised a legacy non-production test tenant account at Microsoft via a password spray attack. The account lacked multi-factor authentication. From there, the attackers leveraged a legacy OAuth application with elevated privileges to access email accounts of senior leadership and employees in cybersecurity, legal, and other functions. The compromise began in November 2023 and was disclosed publicly in January 2024.
Uber — 57 million records exposed through a non-production repository. In 2016, attackers discovered AWS credentials hardcoded in a private GitHub repository used by Uber engineers. Those credentials gave access to an Amazon S3 bucket containing personal data of 57 million users and drivers, including approximately 600,000 US driver's license numbers. Rather than disclose the breach, Uber's Chief Security Officer paid the attackers $100,000 through the company's bug bounty program and had them sign NDAs. The cover-up was discovered in 2017, and the CSO was later convicted of obstruction of justice.
New Relic — customer data accessed through a staging environment. In late 2023, an unauthorized actor used stolen credentials and social engineering to gain access to New Relic's staging environment. Between October and November 2023, the attacker executed search queries and exfiltrated results affecting a small percentage of customers. New Relic confirmed in its security bulletin (NR23-01) that there was no indication of lateral movement to production infrastructure — but the staging environment alone contained enough to cause damage.
These incidents share a pattern: attackers targeted non-production environments with weaker security, and those environments contained real customer data. According to IBM's 2024 Cost of a Data Breach Report, breaches spanning multiple environments (development, staging, and production) cost an average of $5.17 million and take 283 days to identify and contain. Fortifying production while leaving test environments unprotected is like installing a deadbolt on the front door while leaving the back door wide open.
Regulations You're Probably Violating: GDPR, HIPAA, and CCPA
Many development teams overlook a critical fact: data protection regulations do not apply only to production environments. They apply to personal data wherever it exists. The moment you copy real customer data into a test server, that server falls under the same regulatory requirements as production.
GDPR (EU General Data Protection Regulation). The most far-reaching data protection law in the world. Violations can result in fines of up to €20 million or 4% of annual global turnover, whichever is higher. By January 2025, cumulative GDPR fines had reached approximately €5.88 billion (DLA Piper). Article 25 (Data Protection by Design and Default) and Article 32 (Security of Processing) explicitly apply to all environments where personal data is processed — including test and staging. Spain's data protection authority (AEPD) has published official guidance warning that "development and pre-production environments sometimes become the gateway to other environments with personal data."
HIPAA (US Health Insurance Portability and Accountability Act). Applies to all organizations handling healthcare data. HIPAA's penalty structure has four tiers based on the level of negligence, with fines ranging from hundreds of dollars per violation to over $2 million per violation category per year (adjusted annually for inflation). Protected Health Information (PHI) used in test environments must be de-identified per HIPAA's Safe Harbor or Expert Determination methods. The Verizon 2024 DBIR found that 70% of threat actors in healthcare data breaches were internal — and that includes both malicious insiders and accidental mishandling of data, not just deliberate attacks.
CCPA/CPRA (California Consumer Privacy Act). Applies to businesses processing personal information of California residents. Penalties are $2,500 per unintentional violation and $7,500 per intentional violation (with inflation adjustments increasing these amounts over time). Consumers can also seek statutory damages of $100 to $750 per consumer per incident, or actual damages, whichever is greater.
The common thread across these regulations is unambiguous: personal data is personal data, regardless of which environment stores it. A test server gets no exemption. Yet according to K2View's 2025 State of Test Data Management survey, only 7% of organizations fully comply with data privacy regulations in their test environments. That means 93% of companies are operating in a gray zone of potential non-compliance.
Fake data eliminates this problem at the root. No real personal information means no PII, and no PII means no regulatory exposure.
10 Ways Developers Actually Use Fake Data
Fake data isn't limited to the word "testing." It serves a role across the entire software development lifecycle — from the first line of code to production deployment and beyond.
1. Unit testing. When testing individual functions or components in isolation, mock data removes the dependency on external databases or APIs. A function that creates a user gets { name: "Jane Doe", email: "jane@test.com" } as input — predictable, controlled, and independent of any live system.
2. Integration testing. Verifying that multiple services work together correctly requires realistic data flowing across boundaries. Does the payment service correctly receive the order data? Does the API response match the frontend's expectations? Synthetic data that mirrors production schemas catches integration bugs that mocks alone would miss.
3. Load and performance testing. Stress-testing a system requires tens or hundreds of thousands of records. Simulating 100,000 concurrent users, benchmarking query performance on a database with 500,000 orders, testing pagination with large result sets — all of these require bulk fake data that can be generated on demand.
4. Database seeding. When a new developer joins the team, an empty database is useless. Seeding the development database with fake data means they can start working immediately. Include the seed script in version control, and every git clone produces a ready-to-use local environment.
5. UI prototyping. Populating interfaces with realistic names, addresses, and emails — instead of "Test User 1" or "Lorem ipsum" — reveals layout issues that placeholder text hides. Long names, non-ASCII characters (Korean, Japanese, German), and missing fields all behave differently in a real interface.
6. Demo environments. Sales demos and marketing screenshots need convincing data without exposing real customer information. Fake data makes product demos look polished and professional while keeping actual customer data entirely out of the picture.
7. CI/CD pipelines. Automated test data generation as part of continuous integration ensures every build runs against consistent data. When test data is version-controlled alongside test scripts, the "works on my machine" problem shrinks dramatically.
8. Data migration testing. Before modifying a production database schema or migrating to a new system, synthetic data lets you validate ETL processes safely. Column type mismatches, encoding issues, and referential integrity violations surface in testing — not in production at 2 AM.
9. Internationalization (i18n) testing. Testing with only English data misses layout breakage from Korean characters, Japanese address formats, long German compound words, and non-US phone number patterns. Locale-aware fake data catches these issues during development, not after a global launch.
10. Incomplete data testing. Real-world data is messy. Users leave fields blank, enter phone numbers in unexpected formats, or submit forms with missing email addresses. Generating fake data with intentional null values and missing fields tests how your system handles the imperfect data it will inevitably encounter in production.
Best Practices for Test Data Management
Deciding to use fake data is the starting point. Managing it effectively requires a strategy. In January 2025, Gartner published "3 Steps to Improve Test Data Management", outlining key recommendations for software engineering leaders.
Abandon the "production-data-first" mindset. Many teams default to copying the production database because it feels like the most realistic option. Gartner explicitly warns against this habit and recommends synthetic data generation as the primary approach. Copying production data is the path of least resistance — but it's also the most expensive path when you factor in security, compliance, and maintenance costs.
Combine masked and synthetic data. Industry experts recommend a hybrid approach rather than relying on a single method. Masked production data preserves real-world distributions and relationships. Synthetic data covers edge cases and enables bulk generation. Together, they provide the most comprehensive test coverage.
Integrate test data into CI/CD. Test data generation should be automated, not manual. Data scripts should live alongside code in version control. Every build should be able to provision its own test data and run tests against a known baseline. Manual data preparation is a bottleneck that slows down the entire pipeline.
Include realistic edge cases. Data that only tests the happy path is incomplete. Null values, extremely long strings, special characters, non-standard formats, and unexpected data types all appear in production. Tools that let you set a null percentage per field make this kind of adversarial testing far easier.
Apply production-grade security to test environments. Passwordless dev databases, shared credentials for staging servers, test APIs exposed without a VPN — these practices are where breaches begin. Role-based access control (RBAC), encryption, and regular data cleanup should be standard in every environment, not just production.
Use data subsetting. Instead of copying an entire production database, use a representative subset. This reduces storage costs, speeds up test runs, and minimizes the scope of any potential data exposure. For most testing scenarios, a well-constructed subset covers the same ground as a full copy.
How to Generate Fake Data: Tools and Approaches
There are three main ways to generate fake data, each suited to different workflows and team structures.
Code libraries. The most flexible approach. Faker.js (@faker-js/faker) is the most widely used library in the JavaScript/TypeScript ecosystem. Python has Faker, C# has Bogus, and Java has Datafaker. Because you write the generation logic directly in code, customization is unlimited and integration with test scripts is seamless. The trade-off is setup time — and non-developer team members can't easily use them.
SaaS and server-based tools. Services like Mockaroo, Tonic.ai, and MOSTLY AI let you define a schema in a web interface and generate data on their servers. They're convenient, but most have usage limits on free plans (Mockaroo caps its free tier at 1,000 rows, with paid plans starting at $60 per year). The more important concern is that your data schema — which often mirrors your actual database structure — must be sent to an external server. For security-conscious organizations, this alone can be a dealbreaker.
Consider what happens when you enter a users table schema into a server-based tool: first_name, last_name, email, ssn, salary. The generated fake data is harmless, but the schema itself tells the service provider that your database stores Social Security numbers and salary information. That metadata has real value to an attacker.
Browser-based tools. Data generation happens entirely in the browser — no server round-trip, no external data transmission. Your schema and your generated data never leave your computer.
The SudoTool Fake Data Generator takes this approach. All data generation logic runs in pure vanilla JavaScript in your browser, with no external libraries (not even Faker.js) and no server communication. Here's what it offers:
- No row limits — Generate up to 50,000 rows at once (versus the 1,000-row cap on most free tools)
- 5 export formats — Table, JSON, CSV, SQL, and TSV without separate conversion steps
- 35 data types — Names, emails, UUIDs, credit card numbers (with valid Luhn checksums), IP addresses, IBANs, and custom regex patterns
- 5 locales — English (US), English (UK), Korean, Japanese, and German. Name ordering, phone formats, postal codes, and city names are all locale-consistent
- Null percentage per field — Set 0–100% to simulate real-world incomplete data
- Schema save and share — Save to browser localStorage or export as a JSON file to share with teammates
- Smart SQL export — Auto-generates
CREATE TABLEwith appropriate column types and batchesINSERTstatements in groups of 100
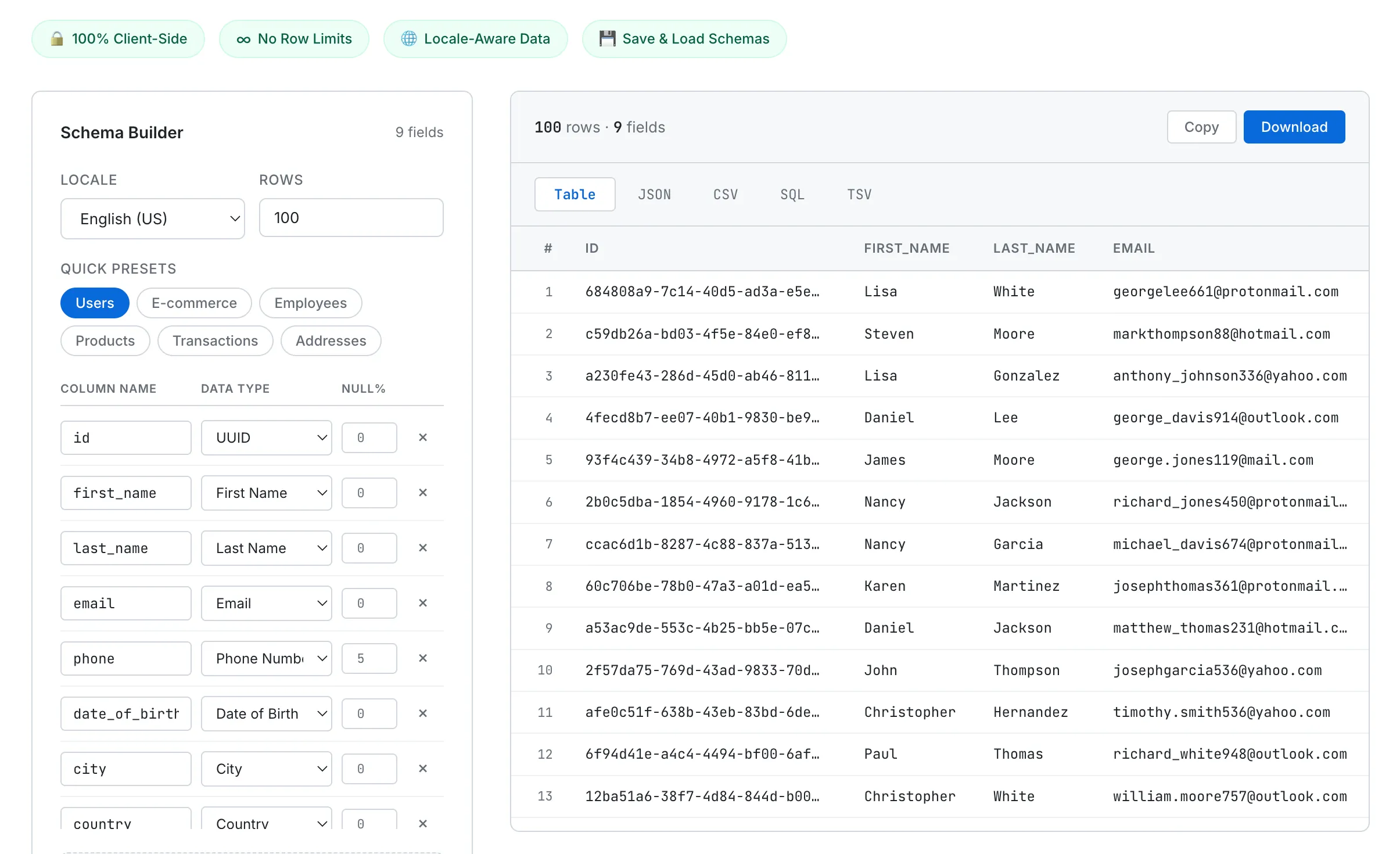
SudoTool's Fake Data Generator — define a schema on the left, generate up to 50,000 rows of locale-aware data on the right. Everything runs in the browser.
No installation, no signup, no cost. Open the tool, define your schema (or load one of the built-in presets for common tables like Users, E-commerce, or Employees), click Generate, and export. Copy JSON to your clipboard or download a SQL file ready to run against your development database.
Frequently Asked Questions
Is fake data the same as synthetic data?
Not exactly. Fake data is typically generated using rule-based algorithms — random names, emails, and addresses that follow realistic formats. Synthetic data is generated using statistical models or machine learning to replicate the distributions and correlations found in real datasets. In practice, the terms are often used interchangeably. For most software testing purposes, rule-based fake data is more than sufficient.
Is it illegal to use real customer data in test environments?
It depends on the jurisdiction and the type of data. Under GDPR, using production data in testing without a proper legal basis and adequate safeguards can constitute a violation. Under HIPAA, using unredacted Protected Health Information in testing is explicitly prohibited. The safest principle: if there's any doubt, use fake data instead.
Can fake data replace real data for all testing scenarios?
For most scenarios — yes. Unit tests, UI tests, load tests, and integration tests all work well with fake data. However, some use cases (such as testing recommendation algorithms or validating machine learning models) may require high-fidelity synthetic data that accurately mirrors real-world statistical distributions. For the vast majority of software testing, rule-based fake data is effective and sufficient.
Does using fake data reduce test quality?
It can actually improve it. A production data copy only reflects the current state of your data. Fake data lets you deliberately include edge cases that haven't occurred yet — extremely long names, null values, non-standard formats, unusual character sets. Catching these bugs early is far cheaper than fixing them in production. A widely cited industry estimate suggests that bugs found in production can cost orders of magnitude more to fix than those caught during development.
How many rows of fake data do I need?
It depends on the test. Unit tests may need only a few dozen records. Pagination testing requires hundreds to thousands. Load and performance testing can require tens of thousands or more. SudoTool's Fake Data Generator supports up to 50,000 rows per generation, covering most development and testing scenarios.
Is browser-based data generation secure?
A browser-based tool that performs all generation client-side is inherently more secure than a server-based alternative — your schema and generated data never leave your machine. That said, you should still manage the generated data responsibly: control where you store it and who you share it with.
Can fake data accidentally contain real people's information?
Theoretically, a randomly generated combination could match a real person — "John Smith" exists thousands of times worldwide. But the probability that a randomly generated name-email-address-phone combination identifies a specific individual is extremely low. From a regulatory perspective, what matters is whether the data was intended to represent a real person. Algorithmically generated random combinations do not meet that threshold.
Start Testing with Better Data Today
Using real customer data in software testing is a habit, not a best practice. With 71% of enterprises still copying production data into test environments, and only 7% fully complying with data privacy regulations in those environments, the gap between current practice and responsible practice is enormous.
Good fake data doesn't reduce test quality — it improves it. It lets you test edge cases that production data doesn't cover, eliminates the risk of data breaches in non-production environments, and removes regulatory exposure entirely. The transition is simpler than most teams expect: open a browser, define a schema, generate data, and export.
If you need realistic test data right now, the SudoTool Fake Data Generator produces up to 50,000 rows of locale-aware data across 35 data types — directly in your browser, with no server communication and no signup.
Curious about the story behind this tool? Read why we built a Fake Data Generator when Mockaroo already exists — the pain points with existing tools, why we wrote every generator function from scratch, and what we'd do differently next time.